|
I am a PhD student in the DYSCO lab at IMT Lucca, advised by Mario Zanon and Alberto Bemporad. I work on practical second-order methods for large-scale machine learning, with an emphasis on Gauss-Newton structure, matrix-free solvers, and JAX-native systems. I also build open-source tooling for curvature-aware training. Prior to starting my PhD, I worked on autonomous delivery robots at Starship Technologies and risk modeling at CompatibL. Email / Google Scholar / GitHub / LinkedIn |

|
|
I study how to retain curvature structure in modern training without paying the full cost of second-order methods. My research focuses on Gauss-Newton approximations, matrix-free solvers, and scalable algorithms that balance curvature quality, stability, and efficiency. |
|
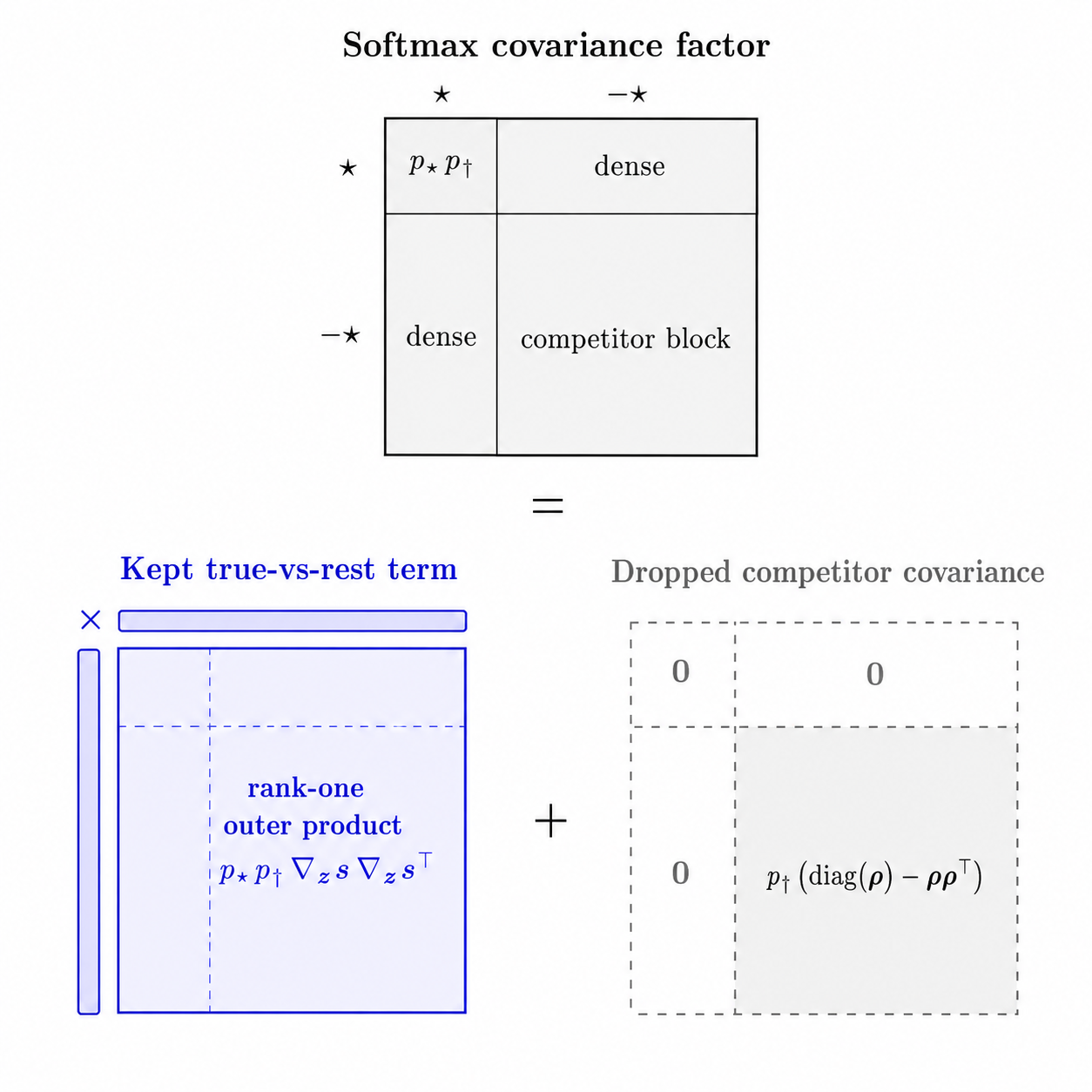
Mikalai Korbit, Mario Zanon Preprint, 2026 arXiv FGN decomposes multiclass softmax GGN into a true-vs-rest term plus a positive semidefinite within-competitor covariance, retains only the former while preserving the exact softmax loss and gradient, and computes damped updates via matrix-free row-space CG without applying the full C-by-C softmax covariance. |
|
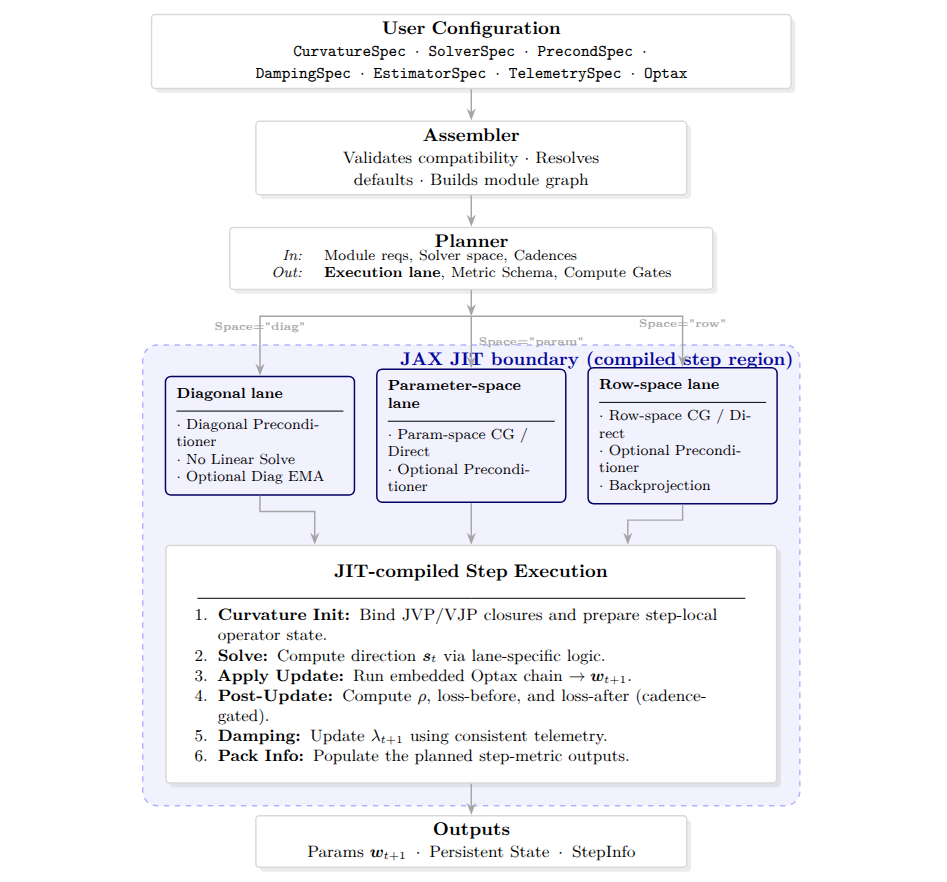
Mikalai Korbit, Mario Zanon Preprint, 2026 code / arXiv We introduce Somax, a systems framework for curvature-aware training that treats a second-order update as a planned JIT-compiled step. It exposes curvature operators, solvers, preconditioners, damping policies, and telemetry as composable modules, and shows that planning and module choices materially affect overhead and time-to-accuracy. |

|
Mikalai Korbit, Adeyemi D. Adeoye, Alberto Bemporad, Mario Zanon Neurocomputing, 2025 arXiv We present EGN, a stochastic second-order optimizer that computes the Gauss-Newton direction by solving an exact low-rank system in mini-batch space, making second-order updates practical when the parameter dimension is much larger than the batch size. |
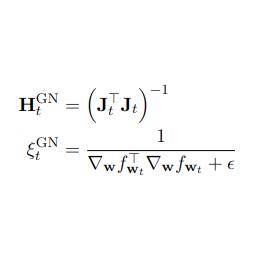
|
Mikalai Korbit, Mario Zanon Preprint, 2024 arXiv We propose IGND, a scale-invariant, easy-to-tune, fast-converging stochastic optimization algorithm based on approximate second-order information with nearly the same per-iteration complexity as Stochastic Gradient Descent. |
|
I develop and maintain Somax, a JAX-native stack for curvature-aware training. It provides a composable framework for implementing, studying, and benchmarking second-order optimization methods at scale. |

|
Mikalai Korbit code / arXiv Somax treats second-order optimization as an explicit training-step pipeline rather than a monolithic optimizer. Curvature construction, linear solves, damping, preconditioning, update transforms, and telemetry are separated into swappable components, then exposed through a stable step interface for JAX training loops. |
|
|
|
|
|
|
|
Kudos to Jon Barron for this template! |